






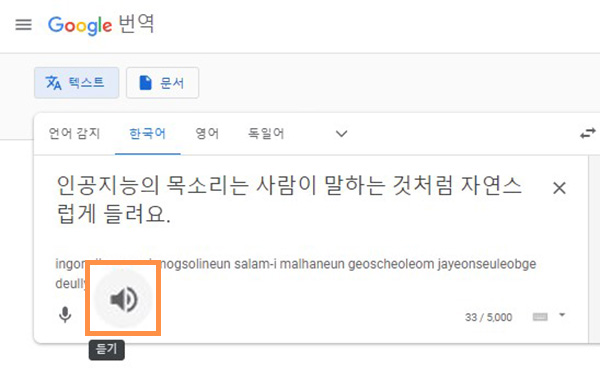
요즘 인공지능스피커에서 흘러나오는 목소리는 마치 사람이 말하는 것처럼 자연스럽습니다. 게다가 나의 취향에 맞는 캐릭터로 설정하면 곧바로 여러 가지 목소리로 출력값을 바꿀 수도 있는데요.
어떤 문장이든 사람처럼 말할 수 있는 이 목소리의 원리가 궁금하지 않나요?
이번 포스트에서는 ai 인공지능의 목소리 원리인 ‘음성합성기술’에 대해 알아볼게요.
텍스트를 음성으로 내보내는 TTS 기술
IT 업계 용어로는 ‘음성합성기술’을 ‘TTS(Text to Speech)’라고 말합니다. 말 그대로 텍스트를 입력하면 해당 데이터에 알맞은 사운드로 출력하는 방식이지요. 그래서 이 기술이 원활하게 구현되려면 풍부한 음성DB, 그리고 텍스트와 사운드 간 매치 정확성을 높이는 게 관건인데요. 과거와 현재의 음성 서비스를 비교해 보면 이 기술이 얼마나 고도화되었는지 느끼실 수 있을 거예요.
과거의 음성 서비스
ARS 서비스만 떠올려보아도 음성합성기술은 꽤 오래 전부터 활용되었다는 걸 알 수 있는데요. 하지만 과거에는 고정된 문장에 일부 단어만 바꿀 수 있는 ‘편집 합성 방식’이 주로 사용되었기 때문에 다소 인위적이고 말할 수 있는 문장은 제한적이었습니다.
쉽게 생각해 ARS 서비스에서 “예약하신 날짜는 12월 1일입니다.”라고 말할 경우, 전체 문장과 날짜에 해당하는 1부터 31까지의 숫자를 전부 녹음해둔 후, 해당 데이터를 편집해 송출하는 방식이었지요.

자연스러운 음성 변환 서비스의 시작
현재의 음성합성기술은 인공지능 기술 발전과 함께 매우 고도화되었습니다.
이제는 자음과 모음, 숫자 등 모든 음성 데이터의 음편을 조합하는 방식이기 때문에 어떤 문장이든 말할 수 있으며, 각 음가의 길이와 높낮이를 세부적으로 다르게 적용해 자연스러운 운율감까지 표현할 수 있는데요.
덕분에 번역기, 시각장애인을 위한 소리책, 타입캐스트 더빙 서비스 등 누구나 쉽게 인공지능 스피커의 목소리를 이용할 수 있게 되었답니다.
한때는 인공지능 로봇에서만 활용되던 TTS 기술이 이제는 우리의 일상을 편리하게 해 주는 서비스로 활용되고 있습니다.
특히 타입캐스트에서는 다양한 언어와 목소리의 TTS 서비스는 물론, 인공지능 활용 캐릭터도 지원하고 있으니 영상 콘텐츠를 제작할 때 활용해 보세요.