

Text-to-speech (TTS) technology has become indispensable for a range of use cases, from business automation to content creation, audio narration, and accessibility. Today’s US English TTS tools deliver increasingly natural speech and realistic sounding voices, supporting everything from e-learning to customer service chatbots, conversational agents, and voice-driven apps. In this guide, we’ll detail the best text-to-speech tools for US English voices, compare providers and their models, and help you choose the right service for your needs.
Which tool fits each use case
- Narration and voiceover: Typecast AI and PlayHT excel with highly expressive, natural narration for audio, video, and audiobooks.
- Enterprise and cloud integration: Amazon Polly, Google Cloud TTS, and Microsoft Azure Neural TTS stand out as providers for reliability and robust TTS APIs. These services are common in large-scale deployments because their models scale well and their API documentation is mature.
- Accessibility and reading: Several platforms offer user-friendly apps for users focused on content consumption, turning text into speech and clean audio.
- Synthetic agents and automation: OpenAI TTS and Typecast AI offer low latency speech generation for conversational voice agents and real time interactive workflows.
Pricing, quality, and deployment trade-offs
When you compare options, consider the cost per character, audio output format, supported languages, and whether the service includes tools for collaboration like shared projects, roles, and review workflows.
- Subscription models (PlayHT, Typecast) favor regular content creators who need predictable cost for ongoing work.
- Pay-as-you-go (Amazon Polly, Google Cloud, Azure) is ideal for scalable deployment when users and audio volume fluctuate.
- Free tiers allow testing before you commit and help validate audio quality, latency, and language coverage.
Voice quality is often highest with premium neural or generative models — Typecast AI in particular stands out because its 700+ voices are sourced from real voice actors rather than generic synthesis.
API access and deployment options can make or break a choice for developers or enterprises, so check TTS APIs, SDK availability, and integration documentation before deciding.
For those building real time conversational agents, also evaluate latency targets and streaming reliability.
Top US English TTS tools compared
Across providers, the core models vary — neural vs. generative — and that affects how natural voices sound in long-form narration, audiobooks, and video voiceover.
Typecast AI
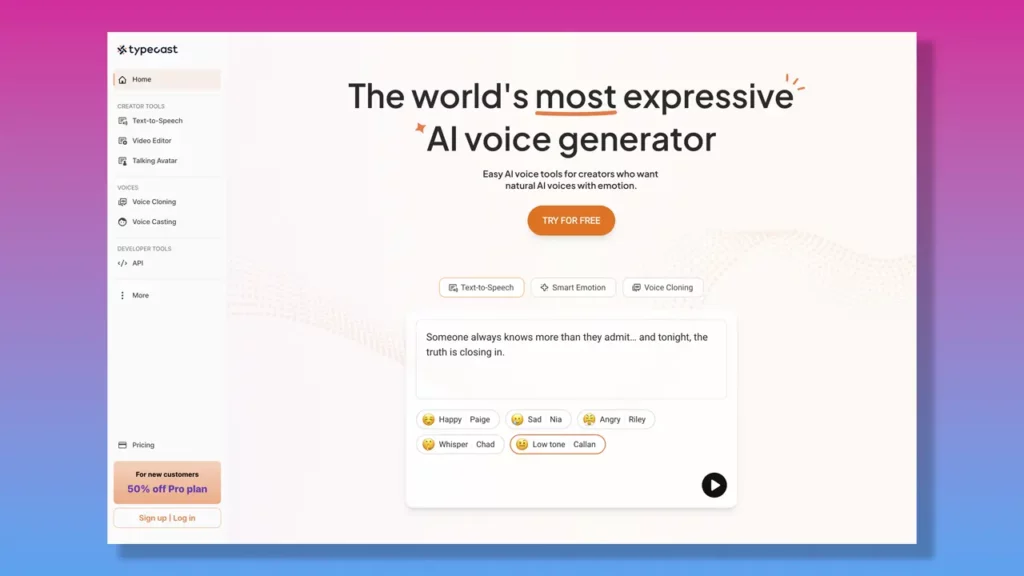
Typecast AI’s text-to-speech is built around three pillars — speed, variety, and control — designed to help you find the perfect voice for any project, because no single voice fits all.
Its workflow is streamlined for fast output: import your script, cast a voice, apply Smart Emotion for automatic adjustments, and download your finished audio.
What sets Typecast apart is its library of 700+ voices sourced from real voice actors — not generic TTS — giving users access to one of the most extensive and authentic-sounding AI voice catalogs available.
Combined with voice cloning and full voice customization, creators can build a unique sonic identity that matches their brand or project precisely.
Typecast’s Smart Emotion feature is a standout: a one-click voice intelligence tool that automatically adjusts emotion, pace, pitch, and speed to match your script — no manual tweaking needed.
For users who want to go further, fine-tuning controls are available on top of Smart Emotion, giving you both the speed of automation and the precision of manual adjustment.
And you don’t pay credits until you’re satisfied with your voice, which removes the risk from experimentation.
The platform is equally suited to individual creators and agencies running bulk production.
Whether you’re generating a single voiceover or queuing dozens of narration projects with different characters, Typecast AI’s studio handles it efficiently — making it a natural fit for content creators, agencies, and enterprises who need natural voice content fast.
Pros:
- 700+ voices sourced from real voice actors, not synthetic defaults
- Smart Emotion for one-click, script-aware emotional delivery
- Fine-tuning controls on top of automatic adjustments for full creative control
- Fast workflow from script import to finished audio download
- Easy bulk production for agencies and high-volume creators
- Voice cloning and full customization for branded consistency
- No credits charged until you’re happy with the output
Cons:
- Paid subscription required for more download time
- API access and pricing can be tiered by usage and characters
PlayHT AI
PlayHT is a leader in podcast-quality TTS, offering 100+ US English voices with natural, human sounding speech and strong conversational prosody.
It features fast, large-scale text-to-speech conversion ideal for media, audio downloads, and TTS APIs that integrate easily with major CMS platforms and automation workflows.
Pros:
- Wide voice and language selection from an extensive library
- Emotion and speech style controls for fine-tuned output
- Podcast-ready audio with quick rendering, even for bulk generation
Cons:
- Higher cost for commercial licenses
- Occasional latency during peak usage for real time playback
PlayHT can also be used as an AI voice generator for text speech workflows that require fast audio generation across multiple languages.
Amazon Polly
Amazon Polly is a staple provider for cloud-based TTS, supporting 40+ US English voices and many languages with reliable service uptime.
It allows granular pronunciation control via SSML tags, offers custom lexicons, and integrates with AWS services — useful for organizations that need scalable audio generation and dependable APIs.
Pros:
- Proven scalability for large-scale text-to-speech conversion across media pipelines
- Flexible API with comprehensive TTS APIs tooling
- Pay-as-you-go pricing with a generous free tier
Cons:
- Some voices can sound less conversational than newer generative models
- Initial setup complexity for certain deployment scenarios
For developers, Amazon Polly is often chosen when reliable TTS APIs, predictable latency, and broad language coverage for global use are top priorities.
Google Cloud text-to-speech
Google’s TTS service is backed by WaveNet and newer neural models, delivering high-fidelity, customizable US English speech with an extensive library of voices across 50+ languages.
It excels at blending voice quality and flexibility, supporting complex SSML features for pronunciation and speech style, and offering enterprise-ready API performance for audio at scale.
Pros:
- Wide range of voices and language options from a deep catalog
- Fast, scalable cloud infrastructure for large-scale media conversion
- Monthly free tier for testing quality and latency
Cons:
- Some setup technicality for new users
- Deeper voice customization requires Google Cloud expertise and training data
Google Cloud is a common pick for multilingual projects that need many languages, strong documentation, and reliable TTS APIs.
Microsoft Azure Neural TTS
Azure Neural TTS offers neural models and customizable US English voices with advanced pronunciation control and broad language options.
Its strengths are high-availability cloud infrastructure, custom voice training, and secure enterprise APIs — making it popular for B2B deployments that require governed, compliant audio generation.
Pros:
- Neural speech synthesis with fine-grained SSML features for style and emphasis
- Custom voice fonts and character profiles
- Strong security, compliance, and enterprise-grade reliability
Cons:
- Requires Azure subscription and initial configuration
- Pricing can be complex to estimate for high-volume workloads
Azure also offers an extensive multilingual voice library and is often used by organizations building regulated workflows that need predictable rollouts and audit-ready documentation.
OpenAI text to speech
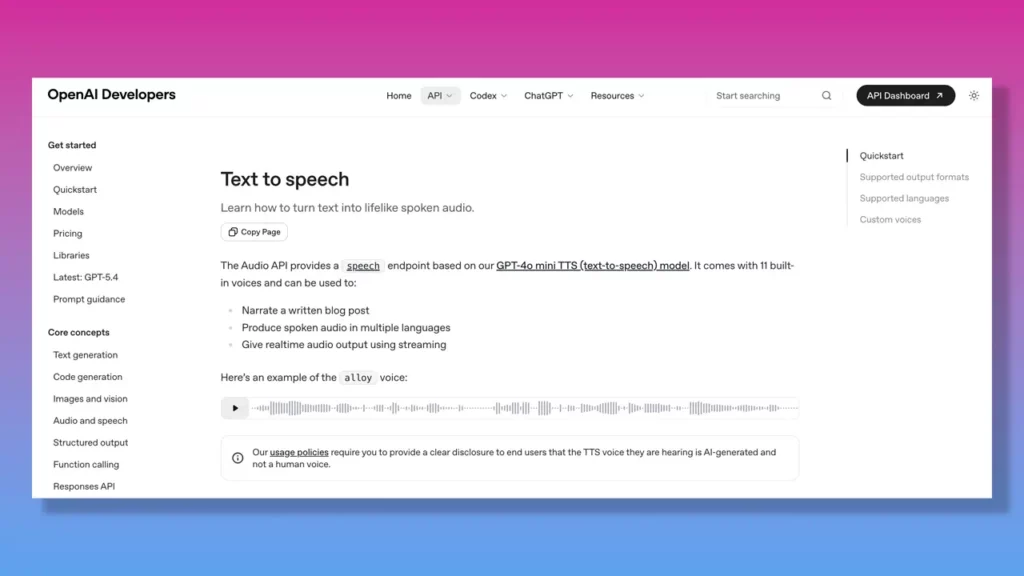
OpenAI’s TTS leverages generative models to offer US English voices with hyper-realistic inflection, conversational speech, and clean audio.
Designed for developers, it’s especially strong in AI-first workflows, chatbot voices, and dynamic content generation where responsive, real time output matters.
Pros:
- Human-like, natural sounding expressiveness
- Seamless GPT integration for presentation and marketing content
- Developer-focused API for fast prototyping
Cons:
- Limited number of voices
- Features evolving rapidly
OpenAI can be a strong AI voice generator when you need conversational voice agents and real time text speech generation driven by modern generative models.
How the leading TTS platforms differ
Extensive AI voice libraries and language options
The size and diversity of a platform’s voice library directly affects how well it serves different use cases and audiences. Here’s how providers compare:
- Largest catalogs: Typecast AI leads with 700+ voices sourced from real voice actors plus multilingual options, followed by PlayHT (100+ voices across dozens of languages) and Google Cloud (300+ voices in 50+ languages). These platforms offer the most extensive AI voice libraries, giving users wide selection for narration, marketing, and localized content. Typecast’s real-actor foundation means its library sounds authentically human rather than algorithmically generated, which is a meaningful difference for creators who need voices that connect with audiences.
- Growing libraries: Azure Neural TTS continues to expand its voice catalog, offering custom voice training to extend available options.
- Focused libraries: Amazon Polly (40+ voices) prioritizes quality and clarity over sheer volume, while OpenAI TTS currently provides a smaller set of highly natural voices.
For projects requiring multilingual output, confirm the number of available languages, regional accents, and whether the platform supports switching voices or languages mid-stream.
Platforms like Google Cloud and Azure publish detailed language and voice option documentation, making it easier to plan global deployments.
Advanced voice customization and pronunciation control
Not all TTS tools give you the same level of control over how words are spoken. Advanced voice customization and pronunciation control features separate professional-grade platforms from basic readers:
- SSML and phoneme-level control: Amazon Polly, Google Cloud, and Azure Neural TTS all support rich SSML markup, letting you adjust pronunciation of proper nouns, acronyms, and technical terms at the phoneme level. This is critical for medical, legal, and financial content where mispronunciation erodes trust.
- Custom lexicons and dictionaries: Amazon Polly and Azure allow you to upload custom lexicons so the TTS engine consistently pronounces domain-specific vocabulary — like brand names, drug names, or product lines — exactly the way you specify.
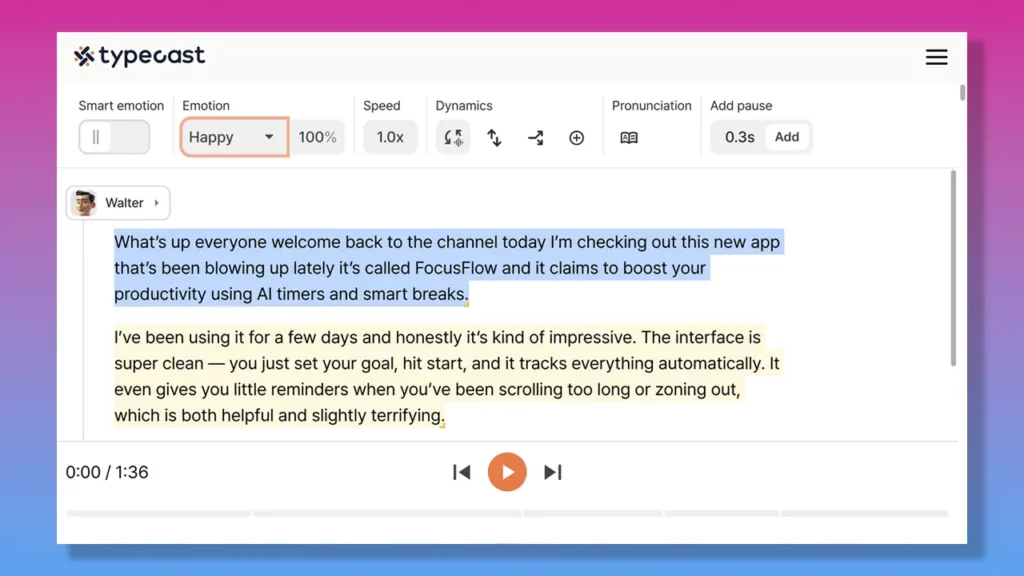
- Voice style and persona tuning: Typecast AI lets you adjust voice characteristics like pitch, speed, and tone through intuitive sliders or API parameters, giving creators granular control without writing SSML by hand. Its Smart Emotion feature handles the heavy lifting automatically, while fine-tuning controls let you override and refine on top — so you get speed and precision without choosing between them.
- Custom voice training: Azure Neural TTS and Typecast AI offer the ability to train entirely new voices from sample recordings, enabling brands to create a proprietary voice that no competitor can replicate. Typecast’s voice cloning paired with its real-actor voice foundation makes custom voice creation faster and more natural sounding than purely synthetic alternatives.
If pronunciation accuracy matters for your content, test each platform’s SSML parsing and custom lexicon features before committing.
Small differences in how platforms handle edge cases — numbers, dates, abbreviations — can significantly affect perceived quality.
Emotion and speech style controls with SSML features
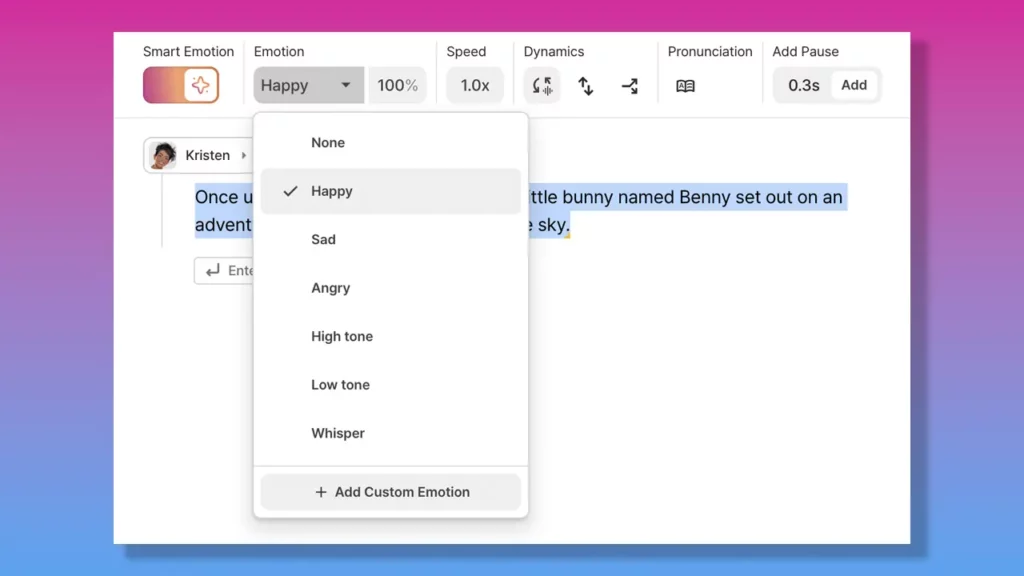
Controlling emotion and speech style is what separates flat, robotic output from audio that genuinely engages listeners.
Here’s how leading platforms handle expressive synthesis:
- SSML-driven emotion tags: Azure Neural TTS provides dedicated SSML <mstts:express-as> tags that let you specify styles like “cheerful,” “sad,” “angry,” or “whispering.” Google Cloud supports similar style parameters on select voices. These SSML features give precise control over emotional delivery without re-recording.
- Smart Emotion (one-click voice intelligence): Typecast AI’s Smart Emotion automatically adjusts emotion, pace, pitch, and speed to match your script — no manual tweaking needed. This is a key reason Typecast is favored by content creators who need expressive output quickly. For those who want additional precision, fine-tuning controls layer on top of Smart Emotion, giving you both automated intelligence and hands-on creative control in a single workflow.
- Contextual emotion detection: Some generative models can infer appropriate emotion from the text itself — a question sounds inquisitive, an exclamation sounds excited — reducing the manual tuning required for natural sounding output.
- Prosody and pacing adjustments: All major platforms support SSML <prosody> tags for rate, pitch, and volume. PlayHT adds pause and emphasis controls through its editor UI, making it accessible for non-technical users who need expressive podcast or audiobook narration.
For long-form audiobook narration or character dialogue, prioritize platforms that offer both automatic emotional inference and manual override — this combination delivers the most natural, engaging listening experience with the least manual effort.
Reliable API and integration for presentation and marketing
For those using TTS in presentation and marketing workflows — from product demo voiceovers to automated video ads and e-learning modules — API reliability and integration quality are non-negotiable:
- Enterprise-grade uptime: Amazon Polly, Google Cloud, and Azure Neural TTS publish formal SLAs (typically 99.9%+ uptime) and offer dedicated endpoints, making them the safest choices for mission-critical marketing pipelines and high-traffic customer-facing deployments.
- CMS and marketing tool integration: PlayHT provides native plugins for WordPress and integrates with popular content management workflows. Typecast AI offers embed codes and direct export to video editors, streamlining the path from script to finished marketing asset — a natural extension of its speed-first workflow.
- Batch and bulk processing: For campaigns that require generating hundreds of personalized audio clips — like localized ad variants or dynamic email narration — Amazon Polly’s batch API and Google Cloud’s long-audio endpoint handle large-scale conversion without manual intervention. Typecast AI’s bulk production capabilities also make it efficient for agencies managing multiple client projects simultaneously.
- Developer SDKs and documentation: OpenAI TTS provides well-documented REST APIs with SDKs in Python, JavaScript, and other common languages, making it straightforward for development teams to embed TTS into custom marketing platforms, presentation builders, and interactive demos.
- Webhook and event-driven architectures: Azure and Google Cloud TTS integrate natively with their respective cloud ecosystems (Azure Functions, Google Cloud Functions), enabling event-driven audio generation — for example, automatically creating a voiceover whenever a new blog post or marketing page is published.
When evaluating API options for marketing use, also consider rate limits, concurrent request caps, and whether the provider offers preview or staging environments for quality-assurance testing before content goes live.
Voice realism and naturalness
- Best-in-class realism: Typecast AI leads in producing voices nearly indistinguishable from real humans — unsurprising given its 700+ voices are sourced from real voice actors. Combined with Smart Emotion’s automatic script-matching, Typecast maintains consistency and natural sounding delivery across both short-form and long-form content where many other tools introduce artifacts or tonal drift. PlayHT also delivers strong realism, particularly for podcast and narration use cases.
- Solid realism: Amazon Polly, Google Cloud, and Azure Neural TTS use neural models for smooth, intelligible speech, with varying expressiveness across languages.
- Functional realism: OpenAI TTS prioritizes clarity and accessibility, making it dependable but sometimes less “performative” in tone.
For accessibility-first projects, prioritize clear speech, stable audio output, and broad language coverage over experimental voice cloning.
Latency and streaming performance

- Lowest latency: OpenAI TTS focuses on real time delivery, providing streaming audio quickly for live agents, voice agents, or instant feedback use cases. Typecast AI’s streamlined workflow — script import to Smart Emotion to download — also delivers fast turnaround, especially for creators who need finished audio quickly without extensive manual editing.
- High throughput: Amazon Polly, Google Cloud, and Azure can process large batches efficiently — ideal for converting libraries of text to audio or scaling multilingual output globally.
- User-friendly streaming: PlayHT offers quick playback in apps for users consuming personal content.
If you’re building voice agents, evaluate real time streaming audio, conversational turn-taking, and test for latency and reliability across providers.
Fast, large-scale text-to-speech conversion for media
When media pipelines need to convert large volumes of text to speech quickly — think audiobook catalogs, localized video libraries, or news narration feeds — throughput and efficiency become the deciding factors:
- Batch API processing: Amazon Polly offers a dedicated asynchronous synthesis API that queues long-form text and delivers completed audio files to S3, making it ideal for publishers converting entire book manuscripts or article archives without blocking other operations.
- Long-audio endpoints: Google Cloud TTS provides a long-audio synthesis endpoint specifically designed for inputs exceeding standard character limits, enabling single-request generation of chapters or full episodes, which is essential for large-scale media conversion.
- Parallel rendering: PlayHT supports concurrent API requests, allowing studios to render multiple chapters, episodes, or ad variants simultaneously. PlayHT’s bulk generation feature is particularly popular with podcast networks that produce dozens of episodes per week.
- Typecast AI’s studio workflow: For creators and agencies who prefer a visual interface over raw API calls, Typecast AI’s studio lets you queue multiple narration projects, assign different voices from its 700+ real-actor library to different characters, apply Smart Emotion across all of them, and export completed audio in batch. This combines the convenience of a GUI with the throughput needed for large-scale media work — and because you don’t pay credits until you’re happy with each voice, you can iterate without cost pressure.
- Output format flexibility: For media workflows, audio format matters. Most platforms export MP3 and WAV, but Google Cloud and Azure also offer OGG Opus (optimized for streaming) and linear PCM (preferred for post-production editing). Confirm that your chosen platform exports the format your editing software or distribution pipeline requires.
- Turnaround benchmarks: In internal testing, Amazon Polly and Google Cloud consistently generate one hour of audio from text in under three minutes using batch endpoints.
For media companies evaluating TTS at scale, the key metrics are characters per second processed, maximum concurrent requests, and whether the platform supports webhook notifications when batch jobs complete — so your pipeline can move to the next stage automatically.
Best TTS tool by use case
Best for narration and voiceovers
Typecast AI delivers narration voices that capture human emotion and storytelling ability, producing high-quality audio for video and audiobooks.
With 700+ real-actor voices and Smart Emotion handling expressive delivery automatically, it’s the most efficient path from script to finished narration.
PlayHT also excels in podcast and audiobook narration with multilingual language options and built-in emotion controls.
Best for enterprise and cloud integration
Amazon Polly, Google Cloud Text-to-Speech, and Microsoft Azure Neural TTS are the leaders here.
They offer industry-standard TTS APIs, strong SLAs, and the ability to handle vast traffic — making them the best choice for software platforms and large businesses.
These providers also publish clearer documentation on security and compliance, which organizations often require for regulated deployments.
Best for real-time voice agents
OpenAI TTS and Typecast AI shine for chatbots, virtual assistants, and live interactions where real time speed and natural conversational responses matter most.
Their TTS APIs are designed for rapid, dynamic speech generation from text to audio.
For real time use, also confirm streaming audio availability, supported languages, and how each service handles conversational interruptions and retries.
Best for presentation, marketing, and media
For presentation and marketing content — including product demos, explainer videos, sales enablement audio, and training modules — Typecast AI and PlayHT offer the best combination of voice realism, style controls, and export flexibility.
Typecast AI’s speed-first workflow is especially valuable for agencies and marketing departments that need to produce large volumes of polished audio on tight deadlines.
Amazon Polly and Google Cloud are preferred when marketing needs fast, large-scale conversion across many language variants.
Best for OpenAI-based workflows
OpenAI Text to Speech integrates with GPT tools and prompt-based generation, streamlining conversational AI, voice agents, and dynamic content creation with modern models and real time audio.
FAQ on choosing a US English TTS tool
Use this practical checklist when evaluating tools: confirm the languages you need, voice and character coverage, audio formats, TTS APIs, pricing, and whether the service supports collaborative workflows for shipping quality content.
Typecast AI is widely regarded as providing the most convincing, expressive US English voices. Its 700+ voices are sourced from real voice actors — not generated from purely synthetic models — and its Smart Emotion feature ensures each script is delivered with appropriate pacing, tone, and inflection automatically.
PlayHT also ranks highly for emotion and performance, especially for creative narration and audiobooks.
Amazon Polly, Google Cloud Text-to-Speech, and Microsoft Azure Neural TTS are best for commercial deployments, thanks to their scalability, reliable APIs, and compliance features.
They cater to enterprise-level uptime, multilingual language requirements, and legal usage needs.
Typecast AI is also a strong contender for commercial content creation where voice quality and production speed are the top priorities — its no-credit-until-satisfied model also reduces risk when testing voices for branded content.
For developers, Google Cloud TTS, Amazon Polly, and OpenAI TTS offer robust, well-documented TTS APIs across common languages.
Typecast AI’s API is gaining traction for use cases where voice realism and customization matter most, with flexible integration options for apps and workflows.
SSML (Speech Synthesis Markup Language) gives you precise control over pronunciation, pauses, emphasis, pitch, and speaking rate.
Platforms like Azure Neural TTS, Amazon Polly, and Google Cloud support rich SSML tags that let you fine-tune how every sentence sounds — essential for professional narration, branded content, and any use case where default pronunciation isn’t sufficient.
Typecast AI takes a different approach with Smart Emotion, which automates many of the same adjustments without requiring SSML expertise — making it more accessible for creators who want expressive results without writing markup.
Yes. Amazon Polly’s batch API, Google Cloud’s long-audio endpoint, and PlayHT’s bulk generation feature are specifically designed for large-scale text-to-speech conversion.
Typecast AI’s studio workflow also handles multi-project queuing and character-based narration efficiently — you can assign different voices from its 700+ library to different characters, apply Smart Emotion across all projects, and export in batch.
Because you don’t pay credits until you’re satisfied with each output, iterating at scale doesn’t carry the cost risk it does on other platforms.
Output formats like MP3, WAV, and OGG Opus are available across most platforms for distribution-ready audio.
Whether you need a voice for your business, a personal project, or sophisticated conversational agents, the US English TTS tools in this guide offer strong options to create natural speech and high-quality audio.
Test their free tiers to validate language availability, pricing, latency, and quality — and expect continued evolution in lifelike synthetic speech generation across every category.