





The launch of Typecast’s SSFM 3.0 marks a significant leap forward in the best voice cloning AI technology.
With its enhanced ability to replicate voices and control emotional expression, Typecast is once again proving why it leads the industry in AI voice cloning software, and emotional and stylistic expression.
This release makes it easier than ever to create natural, expressive, and personalized AI-generated voices that sound almost indistinguishable from real human speech.
For creators seeking the best AI voice cloning tools, SSFM 3.0 delivers unmatched realism, flexibility, and the ability to change the emotion and style of AI cloned voices.

Redefining voice cloning with SSFM 3.0
The best voice cloning AI is at the heart of Typecast’s latest release.
With SSFM 3.0, users can now clone any voice with minimal audio input and then layer on advanced emotional expression.
This is a game-changer in the AI landscape because no other online service currently combines AI voice cloning software with the ability to inject emotions and other styles so seamlessly.
Cloned voices can now express a wide range of emotions, from anger and sadness to joy and excitement.
The new Custom Emotion and Magic Emotion features allow creators to go beyond simple replication and give their cloned voices personality and authenticity.
Whether you’re producing audiobooks, marketing videos, podcasts, or game dialogue, SSFM 3.0 makes AI voices feel truly alive.
Improvements in naturalness
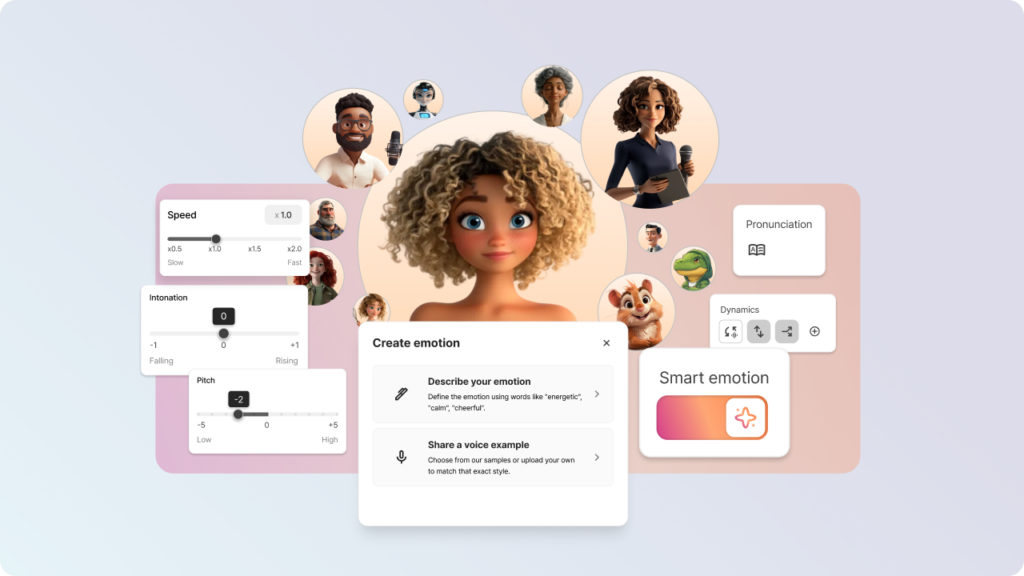
One of the standout features of SSFM 3.0 is its unprecedented naturalness.
By training on over 1.3 million hours of data, Typecast has made speech generation more conversational and realistic than ever before.
Sentences now flow with better continuity, reducing the awkward breaks or tonal shifts that older models sometimes produced.
This upgrade means cloned voices not only sound accurate, but also maintain consistency across longer passages.
For creators working on storytelling or professional voiceover projects, this improvement ensures audiences remain immersed and engaged.
Emotion control features
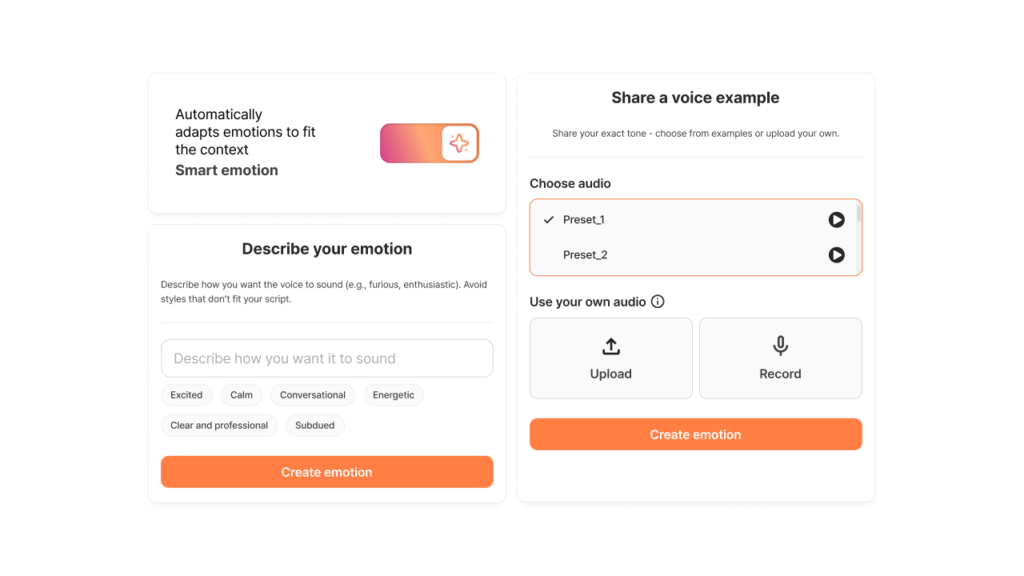
SSFM 3.0 introduces a new level of flexibility with context-based emotion control.
Rather than relying solely on labeled datasets, the model can interpret context and adjust emotions accordingly.
This allows for far more natural and accurate performances in AI-generated speech.
Another breakthrough is the emotion transfer capability. By applying an emotion shifter that uses voice input, SSFM 3.0 can replicate emotional nuance without requiring extensive data labeling.
This not only speeds up production but also expands the range of voices that can convincingly express feelings.
A unique addition is the ability to control the trade-off between speaker similarity and emotional expression.
In earlier models, characters with strong vocal traits struggled to express opposing emotions.
With SSFM 3.0, users can reduce a character’s distinctiveness slightly to unlock greater emotional variety—giving storytellers and content creators far more creative freedom.
Multilingual support

Global reach has always been a priority for Typecast, and SSFM 3.0 strengthens this with improved multilingual capabilities.
SSFM 3.0 officially supports Six main languages:
- English
- Spanish
- Chinese (Simplified)
- Japanese
- Korean
- Vietnamese
In addition, it has the technical capacity to handle over 30 other languages unofficially, making it one of the most versatile AI voice cloning software solutions available.
Phrasing and intonation in Japanese and Chinese have been significantly refined, and overall stability for multilingual generation has been improved.
This ensures more accurate pronunciation and smoother delivery across languages, a feature particularly valuable for international businesses, global content creators, and educators.
Smoother continuity between sentences
One of the biggest challenges in AI speech generation has been maintaining sentence-to-sentence consistency.
Previous models often produced noticeable shifts in tone, pitch, or volume between sentences, which made longer recordings sound artificial.
SSFM 3.0 addresses this issue with sentence-to-sentence continuity (CP), resulting in a smoother listening experience.
This is particularly impactful for audiobook narration, e-learning modules, or long-form podcasts, where consistency across extended passages is critical.
Streamlined usability
Another improvement that makes SSFM 3.0 stand out is its ability to work without a separate text normalizer.
Numbers, abbreviations, and other common cases are now handled automatically.
While rare cases may still require manual editing, the elimination of preprocessing errors ensures a smoother workflow for users.
Even if preprocessing is skipped, the model generates reliable results without system errors.
For users, this means less time spent troubleshooting and more time creating high-quality content.
In preparation: Upcoming possibilities
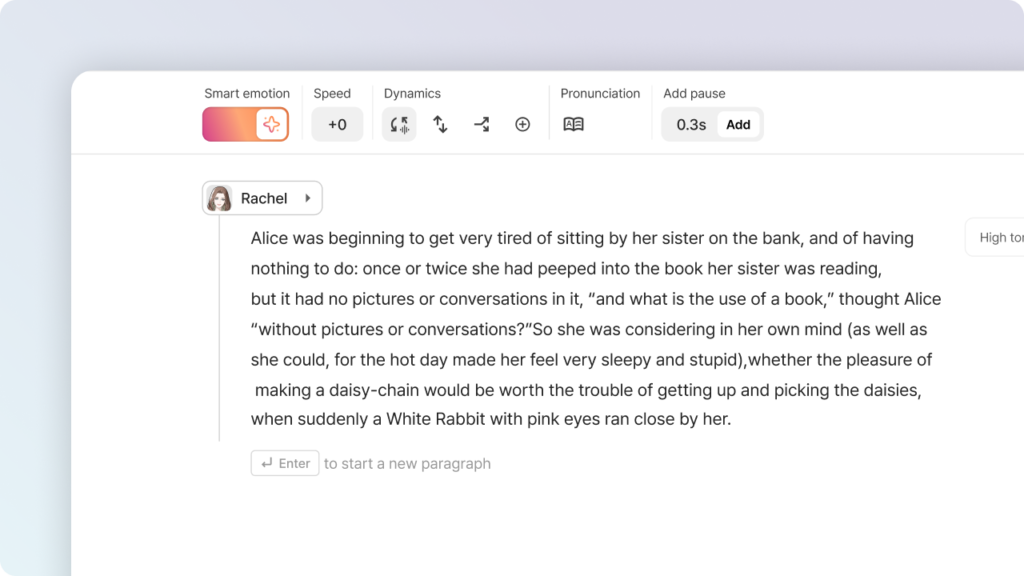
While SSFM 3.0 is already packed with features, Typecast has also outlined a number of enhancements currently in preparation.
These include:
- Accent control, allowing users to adjust fluency when a speaker is using a non-native language.
- True 44.1kHz audio support, ensuring high-quality output, especially for higher-pitched voices.
- Emotion and style control via prompt, offering even finer creative input for situations where context alone is not enough.
Though not guaranteed for this release, these upcoming features highlight Typecast’s commitment to continuous innovation and responsiveness to user needs.
Future plans for SSFM 3.0

Looking ahead, Typecast has even more ambitious goals for its SSFM model.
Post SSFM 3.0 development includes non-verbal expression generation, where sighs, chuckles, or pauses will be automatically added based on context to make voices sound even more human.
Additionally, the company plans to introduce voice design by prompt input, allowing users to create entirely new custom voices through text prompts.
This would give content creators unprecedented flexibility in crafting voices tailored to their projects.
Other refinements, such as improved forced alignment for multilingual accuracy and fine-grained prosody control, are also on the roadmap, ensuring that Typecast continues to push the boundaries of what the best AI voice cloning can achieve.
Why Typecast remains the leader in AI voice expressiveness

Typecast’s history of innovation in text-to-speech sets it apart from other services.
It was one of the first platforms to offer TTS with emotional expression, a feature that has shaped how creators approach digital voiceover work.
By combining this legacy with cutting-edge voice cloning and emotion control, SSFM 3.0 cements Typecast as the best voice cloning AI for creators, businesses, and educators.
For users, the value lies not just in the technology but in the creative freedom it unlocks.
With Voice Cloning, custom emotion, multilingual support, and upcoming features like non-verbal expression, Typecast is giving creators tools that go far beyond standard AI voice cloning software.
Conclusion
The launch of Typecast’s SSFM 3.0 represents a major milestone in AI voice technology.
Its focus on building the best AI voice cloning combined with advanced emotional control sets a new industry standard for realism, flexibility, and creative potential.
With expanded language support, smoother sentence continuity, and a host of upcoming innovations, Typecast has once again raised the bar for what is possible with AI-generated voices.
For anyone seeking the most natural, expressive, and customizable AI voice cloning software available today, Typecast’s SSFM 3.0 is the clear choice.



