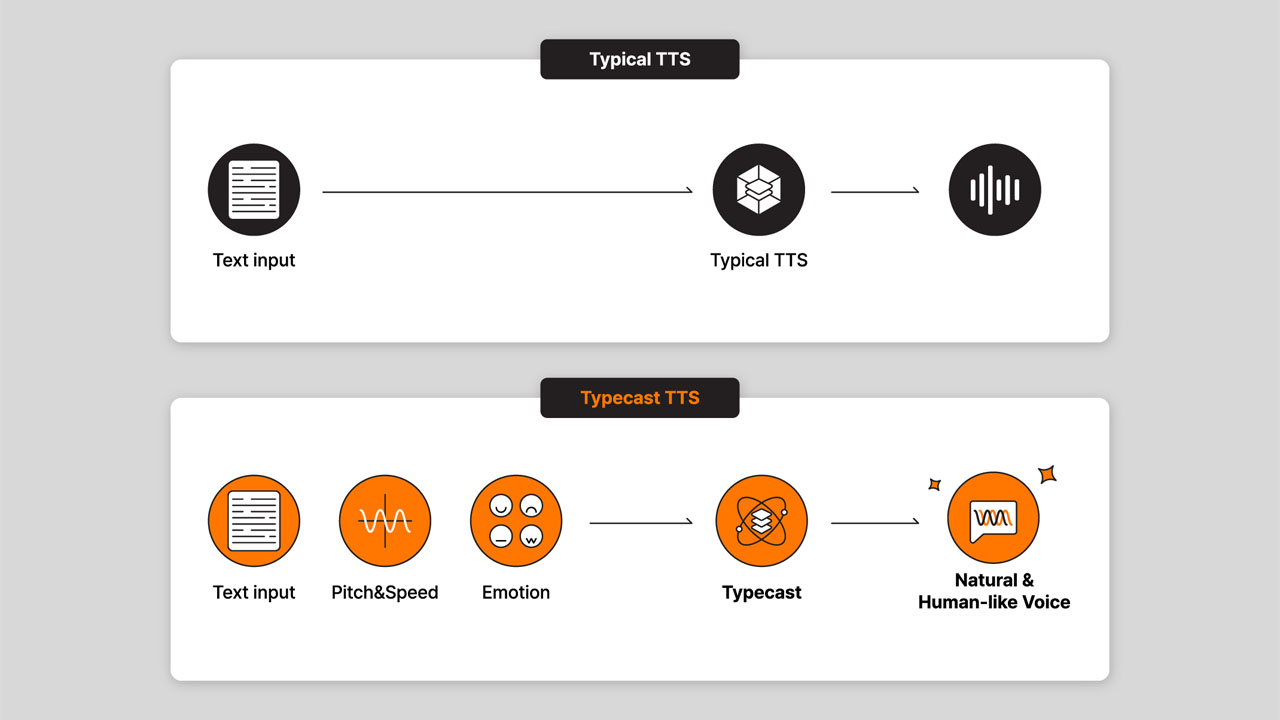




We are introducing the first version of our Typecast Speech Synthesis Foundation Model, or Typecast SSFM v1, for short.
Typecast SSFM is built on top of cutting-edge generative models like the Diffusion model, Auto-regressive model, and GAN.
This powerhouse not only delivers remarkably natural speech but also has the unique ability to replicate voices with just a few seconds of sample speech.
What sets SSFM apart is its impressive controllability, allowing users to tweak certain aspects like emotion, speed, pitch, emphasis/stress, and pronunciation.
We’re excited about the creative possibilities SSFM brings to content creation!
A brief introduction
In recent years, the field of Natural Language Processing (NLP) has seen significant advancements, largely due to the emergence of large-scale language models.
The notable success of these models is attributed to a strategic approach involving the scaling of both model size and training data corpus.
A similar methodology has expedited progress in the field of speech synthesis, leveraging models such as transformer and diffusion.
Researchers have reported that their model can generate speech indistinguishable from human recordings in certain test benchmarks.
However, when faced with real-world scripts and documents, the naturalness of the speech falls short of human recordings. Notably, the lack of control makes it challenging to convey specific nuances required in various situations.
To address these challenges, we have successfully trained a meticulously designed model with a substantial proprietary speech dataset.
In the following sections, we delve into the capabilities of Typecast SSFM and outline the direction of its future development.
Naturalness

The primary performance metric for a speech synthesis model lies in the naturalness of its generated output.
To evaluate this aspect, we conducted an A/B test comparing human recordings with speech generated by Typecast SSFM.
In order to replicate real-world scenarios, as opposed to relying solely on research benchmarks, we gathered recordings from commercial audiobooks that were not part of Typecast SSFM’s training data.
Subsequently, we generated corresponding speech using Typecast SSFM. Participants were then asked to rank the two sources based on their perceived naturalness.
The results revealed that both human recordings and the generated speech were indistinguishable in terms of naturalness.
To experience this seamless quality of Typecast SSFM, take a moment to listen to the following speech sample below.
🗣 Script:
"In a world shrouded in mystery, where secrets lie hidden beneath the surface, one man embarks on a journey that will change his destiny forever."
"Meet John, an ordinary man with an extraordinary thirst for adventure."
"But in his quest for truth, he will face challenges beyond imagination."
"And as he delves deeper into the unknown, he will uncover secrets that will shake the very foundations of his world."
"John's determination knows no bounds as he confronts the darkness that lurks in every shadow."
"With each step, he inches closer to the truth, his resolve unwavering in the face of danger."
"The journey ahead is fraught with peril, but John presses on, driven by a burning desire to unlock the mysteries of the past."
"And as the echoes of his footsteps fade into the abyss, only time will tell what secrets lie waiting to be discovered."Another crucial aspect of naturalness lies in the diversity of the generated speech.
Humans naturally vary their delivery when expressing the same sentence, and audiences often detect machine-generated speech when sentences are consistently delivered in an unnaturally consistantly manner.
Our model addresses this by generating the same sentence with a random varying flow, while maintaining naturalness.
The following examples present the same content but are generated to sound distinctively different.
🗣 Script:
"Another crucial aspect of naturalness lies in the diversity of the generated speech."Expressiveness

After ensuring naturalness, the expressiveness of a speech synthesis model becomes paramount for its utility.
Expressiveness encompasses two key aspects: firstly, the ability to clone the unique characteristics of the target speaker’s speaking style, and secondly, conveying various emotion in line with the content creator’s intention.
Typecast SSFM excels in voice cloning, requiring just a few seconds of a speech sample.
Furthermore, its quality significantly improves with a larger dataset and fine-tuning.
Explore the following examples below to listen to the voice cloning capabilities of Typecast SSFM yourself.
1. Venom from Spider-man
Reference recording.
🗣 Script:
"Pathetic hero, you stand broken and defeated before me, a mere puppet dangling on the strings of your futile resistance."
"Your valor crumbles like ancient ruins, and as I revel in your feeble attempts, remember this moment as the pinnacle of your insignificance - a pitiful spectacle before the majesty of my malevolence."Typecast SSFM output
OpenAI TTS-1-HD output (Alloy)
Elevenlabs (Voice cloning)
*The results were not edited or post-processed.
2. Rapper
🗣 Script:
"AI in my brain. connecting like a train."
"Through the data lanes, where knowledge rains."
"In the code maze, I blaze, no delays."
"Gaining insights, in this digital craze."
"Language magic, matrix tragic."
"Dance to beats, that’s our digital logic."
"Algorithms sing, design’s the thing."
"In an evolving world, where futures swing."Typecast SSFM v1 output
OpenAI TTS-1-HD output (Alloy)
Elevenlabs (Daniel)
*The results were not edited or post-processed. The voice samples are only for demonstration purposes.
With an extensive collection of emotional speech samples in the proprietary dataset, Typecast SSFM can accurately replicate various emotions by inputting specific emotion-cues or referencing emotional speech.
The ensuing emotional speech examples are generated by Typecast SSFM.
3. Emotion control
🗣 Script:
"Oh, I see how it is, you're always there when it's convenient for you."Typecast SSFM v1 output (Sindarin)
OpenAI TTS-1-HD output (Alloy, Shimmer, Echo, Onyx)
Prosody and pronunciation control

When producing content, ensuring that the duration of speech aligns with the content of a video for example is crucial, particularly for dubbing projects.
A speech synthesis model with speed control proves invaluable in such scenarios.
Typecast SSFM excels in seamlessly adjusting the speaking rate without introducing any noticeable errors, such as distorted speech.
By generating speech based on the desired speaking rate rather than relying on post-processing, the resulting speech sounds significantly more natural compared to traditional signal processing methods for altering speaking rates.
🗣 Script:
"Taking it slow sometimes?"
"Absolute gold."
"In the midst of life's chaos, those unhurried moments are pure magic."
"Whether it's a lazy morning or a leisurely stroll, they're the soul-soothing pauses we all need."
"Embracing the slow lane?"
"It's the secret to a happier and more balanced life."Slow
Fast
🗣 Script:
"Hey there, I've noticed that you tend to take your time when talking, and while I appreciate the thoughtfulness, it can sometimes feel like we're wading through molasses!"
"Let's speed things up a tad, shall we? It'll keep things lively and ensure we're making the most of our time together."Slow
Fast
At times, speech generated by a speech synthesis model may convey different meanings based on the emphasized part within a sentence.
The accentuation is mostly influenced by variations in pitch and stress on certain words.
While users may attempt multiple iterations to achieve the desired accentuation, it can be inefficient to spend time generating the same sentence repeatedly, with no guarantee of obtaining the desired result.
Typecast SSFM introduces pitch and emphasis control via a post-processing interface, operating at an pinpoint accurate frame number.
This allows users to exert control over minute details, facilitating a more precise adjustment of pitch and emphasis in the generated speech.
🗣 Script:
"This is our future."
"This is our future."
"This is our future."Large-scale language models effectively understand and use long-term context to capture the precise tense and meaning of homographs in a sentence.
Similarly, large-scale speech synthesis models possess this capability, but in certain instances, understanding the pronunciation of a homograph from the context may be challenging.
In such cases, it becomes important to have manual control over pronunciation, avoiding reliance on automatic pronunciation prediction.
Typecast SSFM provides users with the capability to precisely adjust pronunciation in these specific circumstances.
🗣 Script:
"The bass (bæs/beɪs) was painted on the wall."🗣 Script:
"The soldier took a bow (boʊ/baʊ) after the performance."Future works
So far, we’ve explored the capabilities of Typecast SSFM, foreseeing a transformative impact on the landscape of content creation.
Although the SSFM technology has advanced, there is still room for improvement in the future. In the short term, our main focus will be on enhancing support for multiple languages, especially to meet the demands of content dubbing scenarios.
Furthermore, we anticipate a substantial leap in performance by expanding the model’s training dataset.
At present, SSFM has been trained on 35k hours of proprietary data, so we believe that increasing the dataset by any order of magnitude will bring about significant advancements.
Moreover, although the model can discern the mood of a sentence from its context, providing a specific prompt, similar to to a script for actors, would enhance its accuracy.
Our efforts will extend to refining emotion control, with the aim of making it more intuitive and expressive through natural language input prompts.
Try Typecast’s AI voice generator for yourself!
Typecast SSFM currently offers over 130 AI voice actors for anyone’s audio and video content needs.



