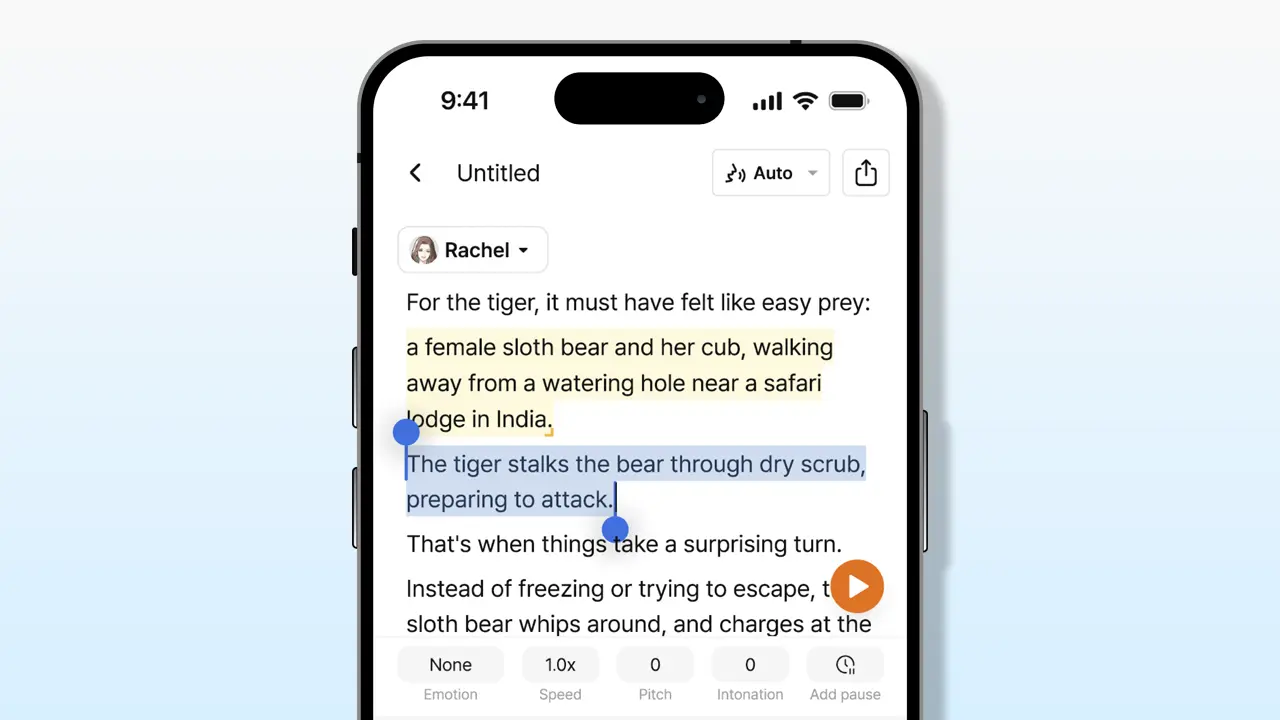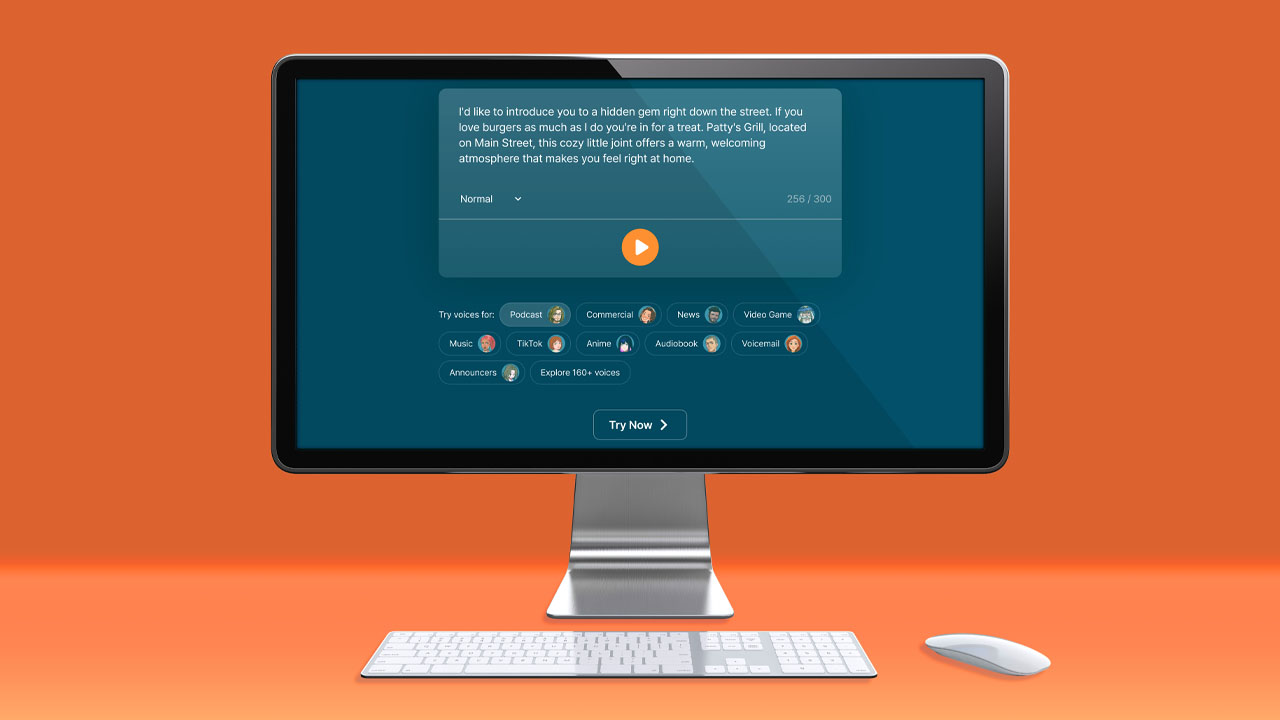





Right now, digital content reigns supreme, and the power of voice is important to many online creators. Over time, our digital toolbox has evolved from simpler text-to-speech online tools to more advanced AI text-to-speech technology.
AI TTS tools are a game-changer for creators since they transform how we consume and create content.
But why are these AI-based tools changing how content creators do their work? Text-to-speech online tools are an attractive option for content creators who want to be more efficient and cost-effective. TTS tools aren’t only for content creators making content as a hobby.
Successful and professional-level creators are adopting these tools to improve the quality of their work. According to recent data, the global TTS market will likely reach $7.6 billion by 2026.
With a market like this, it’s no surprise that content creators are increasingly adopting TTS technology.
We can thank the widespread use of mobile devices, the rising need for accessibility solutions, and even the expansion of digital content for increased AI text-to-speech usage.
One can easily see why TTS tools are popular, but understanding how to bring out their full potential is another matter.
More importantly, whether you’re an AI enthusiast, a student, or a content creator, this comprehensive resource will help you understand how to harness the full potential of text-to-speech.
Let’s explore the world of TTS tools and the many applications, benefits, and cutting-edge advancements shaping their future.
What is AI text-to-speech technology?
By now, you have likely watched content that your favorite creators made with text-to-speech online. Perhaps you watched video content on Instagram, Facebook, or even TikTok. With the current state of TTS software, you may not have realized the creator used AI tools.
At its core, text-to-speech technology converts written text into spoken words. With an easy Google search, you can find hundreds of these voice generators online. However, modern AI-powered TTS systems go far beyond simple conversions and thank goodness they do.
Creator audiences demand or deserve, depending on your perspective, quality content that serves their needs.
Whether a creator makes content for education, entertainment, or even edutainment, the capabilities of TTS tools have surpassed their previous capabilities many times over.
Now, they employ sophisticated algorithms to produce natural-sounding speech that closely mimics human intonation, rhythm, and emotion.
In other words, technological improvements have helped AI text-to-speech software evolve past the retro robotic voices to something nearly indistinguishable from a human voiceover. How did we get here today?
To see exactly how far text-to-speech software has come, visit our page and get to know our virtual voice actors. Make your own voiceover wherever you create content today.
You may not have been around during the critical milestones of TTS development, but seeing where the technology came from can help you see where it’s headed.
The evolution of voice generators

The journey of text-to-speech technology has been nothing short of remarkable.
From the lifeless, monotone voices of early systems to today’s lifelike AI voice generators, the progress has been driven by advancements in natural language processing, deep learning, and neural networks.
The journey of text-to-speech technology is a fascinating one, marked by significant milestones:
- Early systems: Early speech synthesis technology creates computer voices that sound mechanical and unnatural.
- Rule-based systems: These systems improve pronunciation, making the computer voices easier to understand, but they still sound robotic.
- Concatenative synthesis: This is a concept that allows TTS systems to stitch together small pieces of pre-recorded speech to create smoother-sounding artificial voices.
- Statistical parametric synthesis: A concept that makes computer voices sound more human-like when they speak.
- Neural network-based synthesis: These systems use AI to create more natural-sounding computer voices. Deep learning is artificial intelligence designed to behave like a human brain. It uses complex algorithms and vast data sets to learn and improve its performance over time.
With the power of deep learning, deep learning systems analyze patterns in human speech to understand how to produce more natural-sounding and emotional voices.
Today’s AI voice generators represent the pinnacle of this evolution, offering unprecedented quality and versatility. These capabilities have revealed new possibilities for creating engaging, personalized audio content at scale.
After all we’ve discussed about the origins of AI voice tools, there is likely one common question that comes to mind. Is text-to-speech a real voice?
Does text-to-speech use real voices?
You may think that TTS systems are more capable than they used to be, but while that’s true, it’s not the whole truth. As advanced as AI text-to-speech tools have become, they all still require one crucial element: a human voice.
Many other TTS tools use AI to generate synthetic voices that can sound like humans.
These AI systems will use deep learning and complex neural networks to model the sounds of words. To do this, they need vast data sets of text and audio samples to generate speech patterns using the AI voice.
While these advanced TTS systems may work better than the simpler versions scattered throughout the internet, they don’t sound as natural as a human reader.
Other text-to-speech online tools, like Typecast, also use deep learning and neural networks.
Yet, they also use authentic human voices from voice actors and pay them royalties.
In cases like these, we use the actor’s voice to create the most realistic voice content out there. Just think: virtual actors powered by real voice talent at your fingertips whenever you need them.
What about the ethics of TTS voice software?

Since TTS became mainstream, many have questioned the ethics of how companies are creating their virtual voice actors.
One of the main arguments is that TTS technology takes away the job opportunities of hard-working voice actors. While this is a serious concern, many companies are taking steps to ensure this never happens.
Without talented voice actors, we wouldn’t have accessible TTS tools that everyone could use to create engaging voice content.
Since many companies are taking the ethical path to producing high-quality AI voice tools, they created voice cloning technology.
These tools don’t just clone the voices of humans; they keep talented voice actors involved.
Having talented voice actors supporting voice cloning technology is invaluable. Voice cloning opens the doors of opportunity even further for content creators.
Take live video game streaming, for example, where content creators play their favorite game and stream it live to their audience. Many platforms like Twitch, TikTok, and YouTube have fueled this type of content, helping it grow in popularity.
Some creators stream as themselves, but others manifest virtual personas, wear costumes, or use an AI voice generator to disguise their voices.
Sometimes, gaming creators will take their best game clips and use a few AI voiceover lines to narrate about it in a comedic way or offer tips and advice to their audience.
Protestors of AI text-to-speech tools may also be concerned about consent, which has been a massive controversy with AI tools in general.
Many naysayers mention that AI TTS tools make it too easy for criminals to target small businesses, celebrities, or even government officials with scams.
These scams use their voice, cloned using AI technology, to exact revenge or cause harm.
Again, while this is a legitimate concern for many, regulators like the FTC are developing methods to hold bad actors responsible.
The FTC intends to stop this destructive behavior by enacting efforts like the Voice Cloning Challenge. With this challenge, they plan to protect consumers from fraudulent activities where voice cloning harms users.
Moral objections aside, many places have laws that govern the use of a person’s likeness in a way that may harm their ability to make a living.
Fortunately, creators can find many platforms that provide an ethical voice generator.
With these professional voice services, anyone can create content that doesn’t infringe on the rights of the talented individuals who offer their unique voices.
Understanding TTS voice technology may sound quite technical, but you don’t have to be a computer scientist or an audio engineer to use these tools to your advantage.
Five main benefits of using text-to-speech

Many computer scientists and engineers have worked diligently on TTS software to make it more accessible to everyone. While the accessibility of TTS software means that it’s easy to use, it’s also more affordable.
As a small business or individual creator, does it make sense to spend thousands of dollars and spend long hours hiring voice actors or renting studio equipment to produce content?
Depending on the type of content that you’re making, you may only need a few lines from your voice actor. AI text-to-speech tools remove the barriers to creating high-quality voice content.
Text-to-speech software that uses AI gives creators more freedom to express their creativity without the typical industry constraints.
Better yet, what if you could record several lines of high-quality voice content whenever you needed it? This is the new reality, thanks to TTS tools. AI TTS has opened the door of possibilities to those who don’t have the budgets and staffing of larger content agencies.
But, they have also provided other significant benefits too.
- Accessibility: Anyone can create voice content from any device with an internet connection, like your laptop, mobile phone, or tablet.
- Better Content Quality: Unlike the earlier TTS systems that are essentially robotic voice generation software, AI-based systems can account for speech variations and accents. These more advanced tools offer better accuracy and quality in the voice content.
- Scalability: Creators can scale their content creation goals using AI voice tools thanks to advancements in NLP and ML. They can integrate into various platforms, handling large volumes of conversions efficiently. As technology develops, these tools will be able to meet the demands of large-scale applications.
- More Cost-Effective: AI voice changers are a cost-effective alternative because they charge minimal fees for text-to-audio conversion. The service providers also manage the software, reducing the need for creators to have in-house experts.
- Remove Inefficient Workflows: Don’t you hate having to access three different tools to make your audio or video content? Fortunately, text-to-speech online tools simplify voice production, reduce any extra time devoted to retakes, and improve your process for updating content.
Overall, these TTS voice tools allow creators to overcome many cost and time inefficiencies that make it harder to complete and post content.
Creators don’t have to worry about rehashing contracts, interviewing voice talent, or dumping more money into operational costs that don’t produce results.
With these web-based tools, anyone can easily upload a script, make any tweaks, and generate a voiceover.
Some tools, like Typecast, allow creators to make custom avatars with unique voices to add a personal touch to their content.
Text-to-speech solutions also eliminate scheduling bottlenecks, allowing creators to focus on other critical parts of their work.
When high-quality voice tools are within any creator’s grasp, it creates a competitive environment where like-minded individuals must put forth their “A game” and only put out their best work.
If you take a moment to browse the internet, you will see countless TTS software on the market. Still, only a select few usually provide the benefits we mentioned above.
Advances in deep learning and natural language processing made it possible for anyone with the know-how to create their own TTS tool. In other words, the accessibility of this technology has sparked a massive uptick in the number of TTS voice tools.
The rise of text-to-speech online platforms

From a technological aspect, we should praise the accessibility of text-to-speech technology.
The global TTS software market was valued at $2.74 billion last year, and thanks to the demand for these versatile tools, we will likely see it grow to $10.66 billion by 2032.
With so many text-to-speech online tools available, it has given many creators the confidence to experiment and discover the capabilities of each software.
But as we’ve mentioned before, not all TTS platforms are equal. The same is true for creators. Not all creative people are the same; some do it better than others.
That’s why when an audience is looking for video content about “how to start a YouTube channel,” they will search for the one with the highest views, likes, and comments.
Attracting an audience to your YouTube channel takes more than views and likes. Smart creators know that video thumbnails and titles that interest people and draw them in are just as, if not more, important.
We can compare a similar situation with TTS voice tools. Just because the AI voice tool has a lot of users doesn’t necessarily mean it’s of good quality.
When it isn’t, it’s easy to tell the difference between a TTS voice and a human one.
Like unique YouTube thumbnails, the most natural text-to-speech voices attract an audience. The next logical question would be how do creators get natural TTS voices online?
How to get natural text-to-speech voices
One of the most exciting aspects of modern TTS technology is the vast library of voice characters available to use.
With voices that can act as professional narrators, musical voices, and casual conversationalists, voice generators can produce a broad spectrum of vocal styles.
When you find an excellent TTS service, it’s up to you to understand how to use it well.
Types of TTS voices
Learning how to use text-to-speech voices effectively starts with understanding the many types of TTS voices available to creators.
AI voice services with a variety of voice types can cater to a wide range of needs, from simple voice generation to complex, emotion-infused narrations.
Your standard AI voice generator usually has generic voices, some character voices, and some celebrity-inspired voices to add a bit of flair.
Think of the online content you have consumed recently. If it had a voiceover, what kind of voice did it use? For the most part, creators will use adult female and male voices because that is what’s available to them.
Adult voices are usually the most requested voice that creators want because they are widely accepted.
Yet, content demands are changing, and your audience will want variety – something different to keep them engaged.
The best way to accomplish this is to use a text-to-speech online tool that offers voice options from different age groups. Higher quality TTS tools will have access to a full roster of unique voices like:
- Character voices: A superhero? An alien? Maybe a sentient singing android? People create characters for many different reasons. Characters have distinctive voices and are made for a purpose like storytelling or entertainment.
- Celebrity-inspired voices: These are voices that mimic the style of famous personalities. Using voice recordings without permission to train an AI to use your favorite celebrity’s voice could be copyright infringement.
- Male and female voices: The male voice types typically have a deeper, more resonant pitch. Creators may use male voices to express authority, credibility, and professionalism. Generally, a female voice has a higher, brighter pitch and can convey warmth, friendliness, and approachability.
- Children and elderly voices: Children’s voices have a higher pitch and talk at a faster rate. They also work best for simpler language and content that needs a playful tone. Voices for older people have a lower pitch and may talk at a slower rate. These voices work best for content that needs clear language or a soothing tone.
Creators constantly need to produce content that scratches that particular itch of their audience. Still, your content won’t be great just because you can use voices of different age groups.
If your voices are lifeless and lack emotion, your message will come across as flat and awkward – probably not what you’re going for, right?
Adding emotion to text-to-speech

Gone are the days of flat, emotionless computer-generated voices. Modern text-to-speech software can infuse speech with the spectrum of human emotions, which makes the audio more engaging and relatable.
Typecast makes it easy to add any emotion that your content needs.
You can excite your audience by adding a TTS voice filled with anger, sadness, joy, or even anxiety. Is sarcasm more your speed? You can add more depth by adding a unique blend of humor to your voice content with sarcastic voices.
Emotion transforms your voice content and makes your audience more receptive to its message.
But, aside from that, why should creators strive to add emotions to their AI voices?
Why is emotional TTS important?
Some might say that emotion in text-to-speech is the single biggest factor that helps determine the realism of an AI voice compared to a voice generator.
Research studies mention that emotion plays a vital role in human intelligence, rational decision-making, social interaction, perception, memory, learning, and creation. Emotional voice content adds nuance and expressiveness to text-to-speech content.
By providing additional cues about the speaker’s tone and attitude, emotional TTS voices can improve your viewer’s comprehension and help listeners better understand the message.
Emotional voices create a more immersive and enjoyable experience for listeners, making the content more memorable and impactful.
They keep listeners engaged by adding interest and memorability to the content.
Using emotional TTS can foster stronger connections between listeners and the content, increasing the likelihood of viewers performing the desired actions.
Consider a language learning app that employs emotional TTS to offer personalized feedback to users.
The app uses a warm, encouraging voice to praise users for their correct answers and a gentle, understanding voice to guide incorrect responses.
This emotional connection helps users feel supported and motivated throughout their learning journey. As a result, they are more likely to engage with the app regularly and achieve their language learning goals.
In the end, conveying emotions more effectively in your content will improve comprehension, create a more immersive experience, increase engagement, and build stronger connections.
While emotions elevate the quality and impact of text-to-speech content, they also make it possible to create many kinds of voice-based content.
Emotional TTS voices are particularly valuable for:
- Audiobook narration: Voice actors bring written stories to life by reading them aloud, creating an immersive experience for listeners.
- Voice acting for games and animations: Voice actors lend their voices to characters in video games, animated films, and television shows, helping to bring them to life and make them relatable to audiences.
- Customer service applications: Voice actors record automated messages for customer service systems, providing information and assistance to callers.
- E-learning materials: Voice actors narrate educational content for online courses and training programs, making learning more engaging and accessible.
- Marketing and advertising content: Voice actors create voiceovers for commercials, promotional videos, and other marketing materials, helping businesses capture attention and communicate their messages effectively.
- Announcements: Voice actors can be used to deliver live updates or announcements on live-streaming platforms such as Twitch, in community servers like Discord, or anywhere else online. These are usually done by using an automated announcer voice generator via text-to-speech.
Text-to-speech with emotion is meaningful to many creators for many reasons that much we know. But how do AI TTS tools develop the ability to capture emotion and harness it for creators to use?
Techniques for emotional voice generation

We mentioned earlier that you don’t have to be an audio engineer or understand how to create voice models to use TTS tools.
But, it’s important to realize that AI-powered TTS systems use various techniques to add emotional weight to your words.
Creating emotionally resonant TTS voices involves some sophisticated methods:
- Prosody modeling: When someone refers to “Prosody,” they are talking about the words’ pitch, volume, and speed. Prosody modeling involves training the TTS system to vary these factors to communicate different emotions. Creators might try using a higher pitch and faster speech rate to express excitement or a lower pitch and slower speech rate for serious content.
- Sentiment analysis: We can train TTS systems to identify the emotional sensation of text and generate speech with the appropriate emotional tone. If the text is positive, the TTS system might use a more upbeat and cheerful voice.
- Voice acting datasets: Voice acting datasets are recordings of professional voice actors speaking with different emotions. These datasets are another way to train the TTS system to generate speech with realistic emotional expression. The TTS system learns to imitate the vocal characteristics of the actors.
- User-controlled emotion settings: User-controlled settings are a more direct approach to transforming your AI voice content. With these settings, creators can customize the emotional tone and expression of the synthesized speech. They can express different emotions in their script by adjusting the pitch, intonation, and speaking rate as they see fit.
Audio and software engineers wield these techniques and make them work together to produce AI voice avatars that can express a healthy range of emotions.
It doesn’t stop there. While even the most advanced TTS tools can’t effectively use emotional connection, Typecast offers more control over your content quality.
If you want to learn more about how to control the emotions of your virtual voice actors, then you can find our detailed guide on text-to-speech with emotion here.
TTS software should also demonstrate articulation, which involves the precise pronunciation of words and sounds.
Clear and accurate enunciation can help communicate confidence and authority, while awkward pronunciation could confuse or make your audience quickly lose interest.
Pauses are also useful for dramatic effect or to emphasize certain words or phrases. For example, pausing before a key word or phrase can build suspense or anticipation.
Non-verbal sounds such as sighs, laughter, and crying add emotional depth to TTS content. These sounds can help convey emotions too difficult to express through words alone.
Another form of expression that is hard for TTS systems to put into speech is accents. Yet, with the right training data, it’s possible to incorporate the desired accents into text-to-speech software voices.
Mastering accents with AI text-to-speech
One of the most impressive feats of modern TTS technology is its ability to replicate a wide range of accents and dialects.
AI systems can use text-to-speech accents in voice content by training them with accent-specific data.
This can involve using recordings of native speakers with the desired accent and providing the system with information about the phonetic and prosodic features of the accent.
Additionally, software engineers can train the system on written text annotated with accent-specific pronunciation information.
Combining these techniques allows us to teach TTS voice systems to produce speech with virtually any accent we want.
Reading about TTS accents is great, but wouldn’t you rather learn how to master these tools yourself?
Check out this comprehensive resource on text-to-speech accents to discover how accent diversity can elevate your voiceovers.
Other than sounding nice, why does it make sense to train TTS tools how to master accents?
The importance of accent diversity
Accent diversity in TTS voice tools is essential for representing our world’s wide range of languages and cultures.
It allows content creators to create experiences where their audience can interact with technology in a way that feels natural and familiar, regardless of their background.
Accent diversity also helps to break down barriers and promote inclusivity by giving people from different regions and cultures a voice.
Infusing your voice content with emotion and accent diversity is crucial for creating inclusive and engaging audience experiences.
Voice technology has the power to transcend linguistic and cultural boundaries, allowing individuals to connect with content in a more meaningful way.
By leveraging the latest advancements in TTS systems, we can unlock the full potential of voice content, ensuring that every listener feels represented and understood.
How content creators use AI voice generators

These innovative tools have unlocked a new dimension of creativity and efficiency, empowering creators to transform written words into captivating audio experiences.
With a versatile TTS tool, creators are free to explore a myriad of ways they can leverage the technology to captivate audiences, amplify their reach, and produce resonating messages.
The versatility of AI voice technology has led to its swift adoption across many industries and use cases.
Because of its broad accessibility, we can use TTS systems on many devices, including computers, smartphones, and tablets.
They can read many types of text files aloud, including PDFs, Microsoft Word files, and online web pages. Here are several everyday use cases for these voice tools:
Education and e-learning
TTS voice tools have revolutionized e-learning by allowing creators to offer audio versions of course materials.
This feature particularly benefits visually impaired students and individuals with learning disabilities by ensuring they can access and engage with the content.
Creators can also use TTS tools to develop interactive educational resources, like audiobooks, study guides, lectures, and language learning materials.
Overall, these tools enhance the learning experience and cater to a broader range of learners, making education more accessible and inclusive.
Content creation and media
TTS voice tools are valuable assets for content creators who produce work for entertainment purposes.
With a high-quality AI voice generator, nothing can stop you from producing podcasts, videos, animations, and interactive voice experiences for games or apps.
Armed with these tools, creators can rapidly generate voiceovers, narrations, and character voices, enhancing the depth and personality of multimedia content.
TTS tools also streamline the process of creating engaging and impactful audio content, allowing those creators to focus on other aspects of their projects, like faster video editing or designing better graphics.
Business and customer service

Depending on who made the software, voice generators can help you make engaging audio guides, compelling product demonstrations, and informative customer service tutorials.
These tools have the potential to greatly enhance user engagement and satisfaction through content that serves customers better.
You’ve likely seen many examples of companies integrating TTS tools into customer service chatbots and IVR (Interactive Voice Response) systems.
When businesses use AI voice tools this way, they provide a more natural and conversational experience for users, fostering a more intuitive and user-friendly interaction.
In some cases, AI voice characters may also work well in training and onboarding materials for new hires.
Accessibility and assistive technology
There’s no doubt that TTS voice tools elevate many types of online content, but they also serve as valuable aids for individuals with visual impairments or reading difficulties.
These AI voices can dictate words on a page and enable anyone with impaired senses to access digital articles, e-books, and websites, which would otherwise be inaccessible.
TTS tools convert written text into spoken audio, allowing users to listen to the content rather than having to read it.
If you’re a creator and aren’t using AI voice generators to create accessible content – you are missing an opportunity. The first big step into making your content more inclusive is using it to revamp your old content. Marketing gurus are always raving about the merits of ‘reusing your old content.”
Take a page from their book and add accessible audio descriptions for videos and images, making these multimedia resources more inclusive and enjoyable for all audiences.
Online streaming and gaming

Integrating AI-generated voices into livestreams and gaming content has become a growing trend, offering creators new ways to enhance interactivity, accessibility, and branding.
From setting up voice overlays in OBS to crafting unique character personas, there’s a wide range of possibilities that come with this evolving technology.
The mechanics and creative potential of AI TTS streaming are explored in greater detail through real-world applications and platform-specific setups.
This approach not only modernizes how creators engage with their audiences but also helps shape a more inclusive experience for viewers.
As tools continue to improve—enabling greater customization, emotional nuance, and cross-platform integration—the role of AI TTS streaming continues to expand within the content creation landscape, supporting everything from live feedback to character voice automation.
Adopting text-to-speech online tools for your brand
Today, the digital landscape is highly competitive. If you’ve posted a video about The Top 10 RPG Games to Play, someone else has made a better one. But, that’s why content creators need a solid personal brand.
Your brand is what sets you apart from other creators and helps you attract and retain a loyal audience. Let’s dig deeper into why a personal brand is important for video content creators.
- It helps you stand out from the competition. With so many video content creators out there, you need something that makes you unique. Your brand is how potential viewers will notice and remember you over another creator.
- It builds trust and credibility. When your audience knows who you are and what you stand for, they are more likely to trust you and your content. This trust is fundamental for building a loyal following – you can’t grow without one.
- It helps you connect with your audience on a deeper level. When you share your personal story and values with your audience, they’re more likely to feel connected to you and your content. This connection is what will keep them coming back for more.
- It can help you monetize your content. Many creators are hobbyists, but a select few want more from their online presence. A strong personal brand can help you attract sponsorships, advertising opportunities, and other revenue-generating partnerships.
You may still be asking Why does my audience need to support my personal brand? You need an audience to follow your personal brand because it’s a way of supporting you and your work.
When you create content that is authentic and true to yourself, you’re giving your audience something valuable and meaningful.
When your audience genuinely supports you, they want to see you succeed and are more likely to do so if they feel connected to you and your brand.
By investing in your brand, you’re cementing your future as a content creator.
So, take the time to develop a solid personal brand that will help you stand out from the competition, build trust and credibility with your audience, and achieve your goals.
Are you ready to stand out instead of disappearing in the sea of YouTube purgatory? We’ve written a guide on the best text-to-speech applications for your brand and other creative endeavors.
Combining YouTube and text-to-speech: A perfect match

Markiplier, arguably one of the most successful YouTube personalities today, says that to be a successful creator, you need to do it for fun, be unique, and always be yourself.
More importantly, highly successful YouTubers know that your brand is the style behind the idea. As a video content creator, your idea is only the first puzzle piece.
From there, creators have to present their ideas in a way that interests their audience and keeps them coming back.
With over 38 million subscribers, Markiplier has committed to his brand and leverages it to make content his audience enjoys.
At the same time, he realized a long time ago that genuinely connecting with his audience on a personal level and being vulnerable would have more of an impact.
Because of his success, Markiplier expanded his content beyond gaming, organizing charity events, and raising millions to support amazing causes.
While many YouTube creators won’t have the same commitment and energy he does, they have other tools that may even the odds.
YouTube creators are turning to AI voice tools to enhance their content and streamline production time.
Resourceful creators can use the benefits of text-to-speech online tools to provide their viewers with high-tier content.
The benefits of TTS voice for YouTube creators
There is no denying that TTS adds a dynamic element to videos. It can effortlessly capture the viewers’ attention and make content more relatable.
Creators use it when they want to reach a global audience by translating content into multiple languages. TTS also enables creators to produce innovative content by offering a library of voices, tones, and languages.
Some would argue that the most important thing TTS voice can do is help you maintain a consistent voice across all your content.
Others would say that TTS technology makes the creative process less tedious and saves costs associated with traditional voiceover production.
Best practices for using TTS on YouTube
When using text-to-speech online technology, creators should consider several factors to craft natural-sounding audio. First, your chosen voice has to fit the tone and style of your content.
You wouldn’t use Spongebob’s voice to make healthcare content about mental health – it doesn’t fit.
However, Typecast offers over 160+ different voices for YouTube with text-to-speech, so you have plenty of options if that is the type of content you create.
Next, pay attention to the pacing of the voice. TTS tools that read too quickly or slowly can be difficult to understand.
This doesn’t just apply to YouTube. Creators can and should apply the best practices anywhere they are helpful to create engaging and accessible content.
Did you know you can use an AI text-to-speech voice changer to make music?
Creative text-to-song and beyond

The versatility of AI TTS extends into many creative domains, with one particularly intriguing application being text-to-song.
It shouldn’t surprise anyone that TTS voice systems are coming to the music industry. With AI-powered platforms, music producers can automate complex and time-consuming tasks, freeing up more time for creativity and experimentation.
AI is already working behind the scenes in your favorite music apps to create personalized music playlists that adapt to your moods and activities. This technology will analyze an individual’s preferences and generate playlists that resonate with them.
AI rap and AI-generated music are rapidly emerging fields that relentlessly push the boundaries of what’s possible in music creation.
Artists use AI to create unique soundscapes, blurring the lines between humans and machines.
What is AI rap?
AI rap is an innovative genre of music where AI algorithms generate rap lyrics and melodies.
These AI-powered algorithms meticulously analyze extensive datasets of existing rap songs to discern patterns, structures, and rhyming schemes.
As a result, AI rap artists can create intricate, witty, and sometimes indistinguishable lyrics from human-written rap.
This unique blend of AI technology and musical creativity pushes the boundaries of music production and offers a fresh perspective on the rap genre.
The rise of AI-generated music
AI-generated music creation is growing, enabling creators to express themselves with diverse musical genres, from classical to electronic. And AI-generated music is gaining more ground every day. In fact, 50% of musicians believe AI will be composing Top 40 hits in the next decade.
These complex algorithms compose entire songs that encompass melodies, harmonies, and rhythms. With AI voice generators, anyone can input specific musical elements, and the AI generates complementary parts.
Advanced TTS systems even have custom avatars for singing or rapping and the lyrics you write.
We can appreciate the quick advancement of AI-generated music and trace it to the accessibility of vast music datasets. But even this technology hits a few snags now and then. AI-generated rap presents exciting possibilities, but it also raises questions about:
- Making sure that AI text-to-speech voice changers are unique and original rather than simply imitating existing music.
- How text-to-speech online tools will capture the emotional depth and nuance that often come from human musicians’ experiences and interpretations.
- The ethical considerations include AI-generated music’s potential to replace human musicians or how to guarantee that engineers train AI systems on diverse and representative datasets.
Like any new technology, laws and regulations trail behind AI’s rate of advancement. In time, stakeholders will create policies that keep AI voice tools in check.
At present, text-to-speech online tools make music creation more accessible, allowing people without traditional musical training to express themselves.
Despite the challenges, AI rap and AI-generated music have the potential to chart a new course for the music industry, offering new avenues for artistic expression and pushing the boundaries of what we consider “music.”
To push the capabilities of TTS technology further, creators need to understand how to apply everything they know about it to their creative process.
How to transform your text into voice content?
Throughout this article, we’ve discussed how creators can use AI to their advantage, what kinds of content they can create, and how to improve the experience using TTS tools. However, every creator has a different way of engaging their inner muse and putting their best foot forward.
Here’s a quick guide to using Typecast for your voice content. It’s perfect for any creator who is just now giving TTS tools a try or wants to know how to make better content.
- Step 1: Drag and drop your text or type it directly into the versatile Typecast editor.
- Step 2: Choose from 400+ AI voice actors to match the mood and context of your text.
- Step 3: With our editor, you can adjust the tone, style, and speed of the voice to your liking.
- Step 4: When you’ve crafted your next awesome voiceover script, click “Download” to save your audio file in WAV or MP3 format.
The future of AI TTS software

As we look ahead, the future of AI voice technology is brimming with exciting possibilities. As AI continues to evolve, so does the potential of text-to-speech technology. The future promises even more natural and versatile voice generation capabilities.
Yet, responsible creators wouldn’t be doing their due diligence if they didn’t consider the future of TTS tools. They are only going to get better in the future. Here are a few of the exciting developments that we can expect to see:
- Real-time voice cloning: This technology will allow you to create a voice that sounds just like your own or anyone else you choose. This could be used for various reasons, like creating personalized voice assistants or narrating audiobooks.
- Multimodal AI integrating speech, text, and visual elements: This technology will allow TTS voices to interact with other forms of media, such as text and images. You can create more immersive experiences like interactive stories or educational games.
- Personalized voice assistants with more distinct personalities: In the future, voice assistants will be able to learn more about you and your preferences, adapting their voices and responses accordingly.
- Emotion-adaptive TTS voice systems: These systems will be able to adjust their tone and inflection to match the emotion of the text it’s reading.
As TTS tools continue to improve and become more capable, they will undoubtedly reshape how we interact with digital content. Over time, it will make information more accessible and engaging than ever before.
All that’s left is open-minded creators accepting the reality of text-to-speech online tools and embracing the power of TTS software.
Embracing the TTS voice revolution
As we’ve explored throughout this article, TTS technology is transforming how we create, consume, and interact with digital content.
From education to entertainment and the accessibility of creative expression, the applications of TTS are as diverse as they are impactful. We will need to keep our eyes on the rapid growth and improvement of TTS technology.
We will also need to be mindful of:
- The accessibility and versatility of online TTS platforms
- The importance of emotions in creating engaging voice content
- The wide-ranging applications of TTS across many domains
- The future trends shaping the evolution of voice technology
It’s clear that text-to-speech online tools will continue to play an ever-present role in our digital lives.
Whether you’re a content creator looking to enhance your productions or simply an individual fascinated by the possibilities, the world of text-to-speech offers endless opportunities for exploration and innovation.
By embracing this technology and staying informed about its developments, we can all contribute to and benefit from the ongoing voice revolution.
The key to leveraging AI voice tools lies in understanding its capabilities, choosing the right tools, and applying best practices across various use cases.
As AI continues to push the boundaries of what’s possible in speech synthesis, we stand on the brink of a new era in human-computer interaction – one where the power of voice is more accessible, expressive, and transformative than ever before.